III. INSTITUTIONS
Раздел основан на data_website_original.xlsx, а точнее на фрaкционализованном датасете на основе data_website_original.xlsx.
Унификация связки organisation_full - country - region была осуществлена через вменение моды.
ОБНОВЛЕНИЕ III раздела
Для обновления III раздела пользоваться новым файлом data_website_revised. Однако на прошлом этапе этот файл дальше преобразовывался по следующему запросу. Если код остался, то, наверное, можно повторить.
Дублирую из телеграма. Красным мои сейчас пометки:
Изначальный датасет data_website_original (у нас сейчас data_website_revised). Прежде начала работы к нему по id добавить переменную q из data_website (думаю, что лучше брать из более полного файла full_data_precise_original переменная Q, так как в файл добавились новые строчки). - СДЕЛАНО ✅
(1) Страны и организации
Можно взять 15 стран с наибольшим вкладом. Указывается количество организаций и количество публикаций, а также процент от количества всего организаций и публикаций.
(2) Топ-институций в виде графика
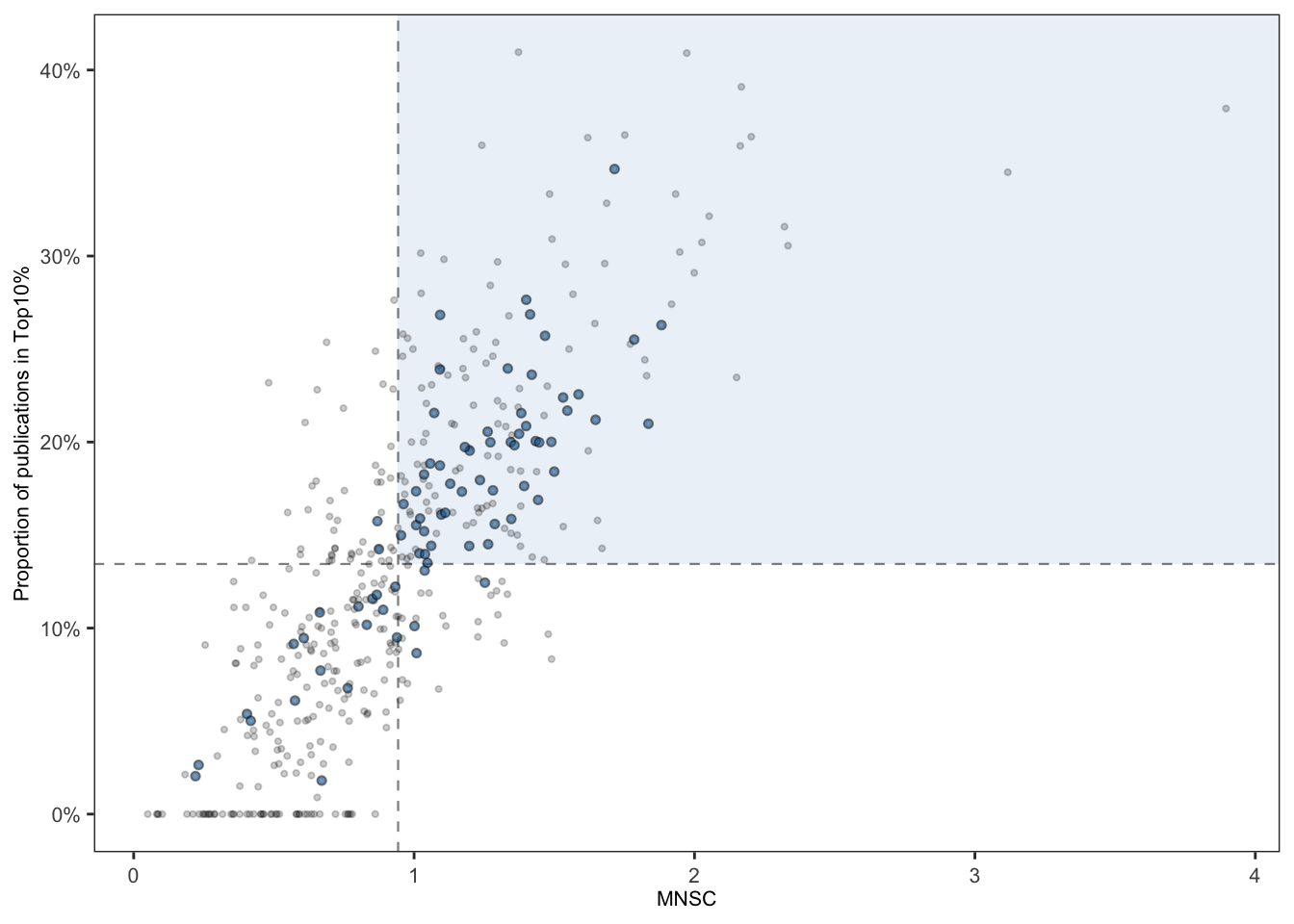
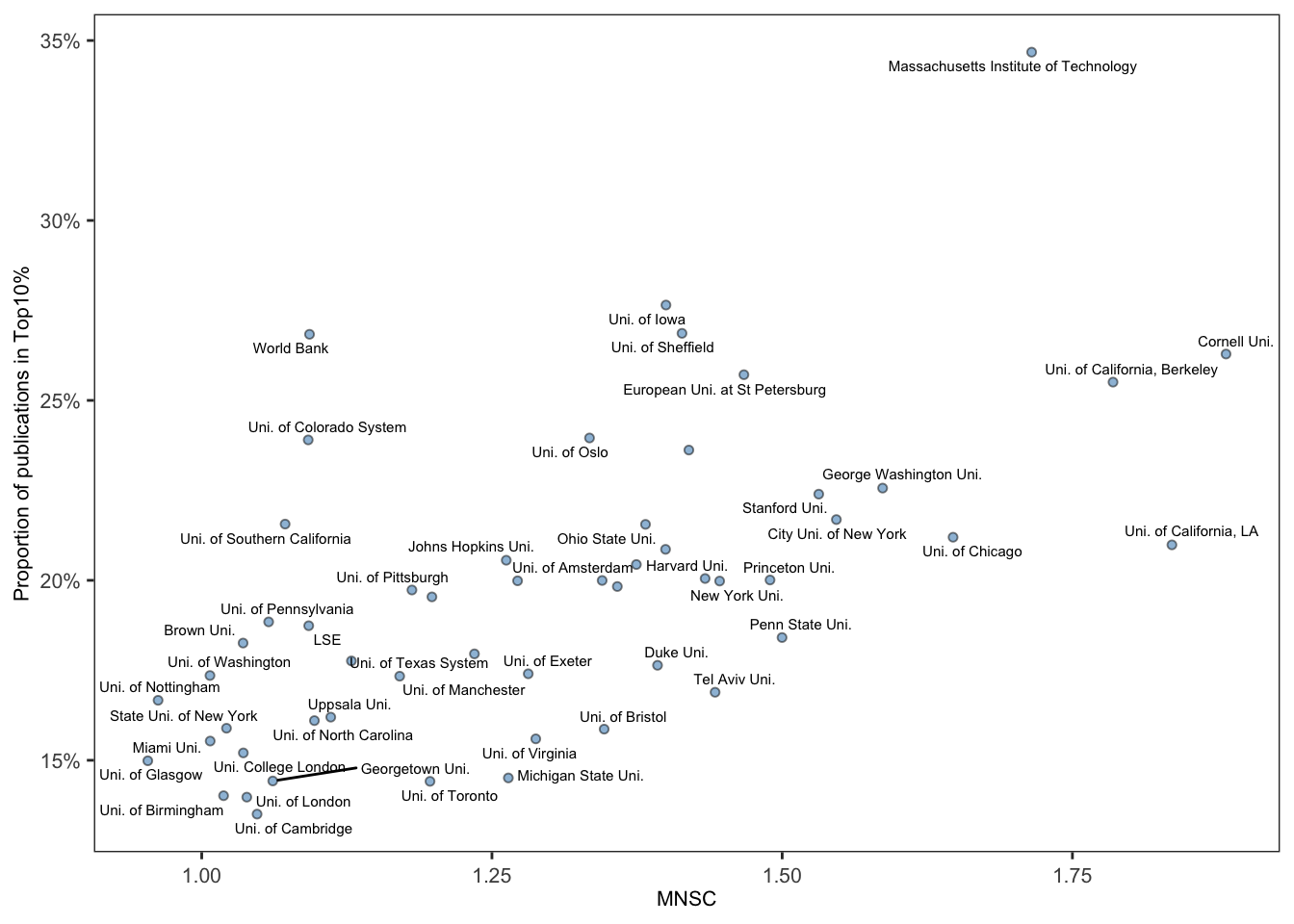
- Первый вариант графика: Давайте попробуем график со всеми точками, цветом как вы предложили > 50 и < 50. Размер кружка можно попробовать по количеству публикаций. Поделить на квадранты по средним график и показывать среднее цифрами. Из правого верхнего квадранта дать названия 10 университетам с наибольшим % в 10% публикаций.
квадрантили сделаны средними ПО ВСЕМ ИНСТИТУЦИЯМ. пока график интерактивный, красивые статичные лейблы буду рисовать руками. сейчас всплывают все названия организаций и коорединаты по которым они построены, а так же число статей у красных точек, чтобы удобно было писать текст. Все подписи / размеры / буду делать в статике после того как мы выберем окончательный вид графика
(3) Топ-институций
сами значения показателей в виде таблицы. Взять университеты, которые одновременно выше среднего по 2 нашим показателям.
среднее для двух показателей, с которыми будем сравнивать (их же мы видим как mean на рис Версия 1)
| mean(top_10_fr_sh) | mean(mncs_frac_mean) |
|---|---|
| 13.44597 | 0.9430216 |
(4) Организации и динамика их вклада.
ЗДЕСЬ ПОД ТОП ОРГАНИЗАЦИЯМИ (столбец our_top_org) имеются ввиду организации, которые отвечают трем требованиям:
>= 50 публикаций
top_10_fr_sh> среднего значенияtop_10_fr_shдля ВСЕХ ИНСТИТУЦИЙ (НЕ ДЛЯ ИНСТИТУЦИЙ С >= 50 публикаций)mncs_frac_mean> среднего значенияmncs_frac_meanдля ВСЕХ ИНСТИТУЦИЙ (НЕ ДЛЯ ИНСТИТУЦИЙ С >= 50 публикаций)
Взять наш топ организаций и показать, как по периодам (у нас их три) распределяются статьи. Мы отвечаем насколько заслуги распределены между периодами. Нет ли историй у которых были бы полностью заслуги в прошлом, но есть новички. 1990-2020 % pubs of total – это доля публикация организации взятая от всех публикаций в датасете Далее 3 колонки доля уже от 1990-2020 N pubs самой организации. Возможно лучше давать N и долю в скобках.
На всем датасете дать такие цифры: для каждого нашего региона посчитать среднее как для всех организаций распределяются по 3 периодам публикации. То есть будет цифра для North America сколько в среднем для ее организаций процентов публикаций вышло в первом, втором и третьем периоде.
(5) Топ организаций специализируется ли на чем-то одном?
В колонке указать – название области, по которой больше всего статей (2 и 3 место также), количество статей по этой области и доля публикаций от числа публикаций этой организации - name,N and %.
FIELDS
Research areas
важно! на третьем месте может быть сразу две области. берется только одна. первая по алфавиту. для топовых универов такое было 1 раз.
Прицепить к всплывающему лейблу название области не так просто, поэтому только смоетреть в таблице.
(6) По всем ли периодам был одинаковый топ?
Для этогих задач был сделан новый датасет с фракционализацией, так как у нас показатели цитируемости и top раньше рассчитывались для всего периода 1990-2020.
Для групп 1990-2000, 2001-2010, 2011-2020 показатель total_pub >=50 на основе которого мы, в том числе определяем топ, превращается в total_pub >= 16.66 (то есть, 50 / 3) для соответствующего периода 1990-2000, 2001-2010, 2011-2020.
Если попробовать разбить датасет по нашим периодам и по нашему алгоритму найти для каждого периода свой список вузов, которые попали в четвертый квадрат (выше среднего и по нормализованной цитируемости и по доле публикаций в 10%). Тогда результат вот так можно представить. И может быть подсветить цветом название вуза (из числа наших топов за весь период), если он был в этот период в топе.
| mean(top_10_fr_sh) | mean(mncs_frac_mean) | period |
|---|---|---|
| 13.44597 | 0.9430216 | 1990-2020 |
| 14.43272 | 1.0981965 | 1990-2000 |
| 12.62818 | 0.9093282 | 2001-2010 |
| 12.95818 | 0.8252276 | 2011-2020 |
И еще нужна такая простая табличка. Дать список наших университетов и сколько раз они попали в топ за три периода (то есть максимальное количество 3 должно быть).
максимальное значение 4, так как по принятым критериям попадания в топ, попадание в топ в диапазоне, например, 1990-2000 не значит, что институция попала в топ всего периода 1990-2020.